Pasado, Presente y Futuro de las Bases de Datos
“Lo que fue innovador ha sido replicado. La tecnología parece haber llegado a su límite. ¿Qué nueva funcionalidad se puede adicionar en el software que se usa en mi empresa?.”
La perspectiva anterior me parece incorrecta. Por ejemplo, hace una década había quienes aseguraban que las bases de datos eran tecnología “madura”, pero hoy es una de las áreas del cómputo que presentan mayor dinamismo. Analicemos su historia y perspectivas a futuro.
Antecedentes
 En 1960 apareció una primera generación de base de datos para permitir el intercambio de información entre sistemas. La memoria RAM y el espacio de almacenamiento eran extremadamente restringidos. Para cambiar de administrador de base de datos, era necesario reescribir la aplicación debido a la variedad de lenguajes y características. Fue un modelo tan cerrado que hoy hay empresas que continúan dependiendo de productos como IMS de IBM, IDMS y DATACOM de CA, DMS II de UNISYS y Adabas de Software AG.
En 1960 apareció una primera generación de base de datos para permitir el intercambio de información entre sistemas. La memoria RAM y el espacio de almacenamiento eran extremadamente restringidos. Para cambiar de administrador de base de datos, era necesario reescribir la aplicación debido a la variedad de lenguajes y características. Fue un modelo tan cerrado que hoy hay empresas que continúan dependiendo de productos como IMS de IBM, IDMS y DATACOM de CA, DMS II de UNISYS y Adabas de Software AG.En la búsqueda de una nueva forma de acceder datos que fuera independiente de la aplicación, se aplicaron modelos matemáticos para crear un paradigma relacional. System /R de IBM fue la primera implementación de la propuesta del Dr. E. F. Codd. Se generaron distintas propuestas para un lenguaje de consulta universal, tales como SQL, DLL y DML. Triunfó el primero, que no gustaba a los puristas pero era más sencillo. En ese momento la memoria RAM continuaba siendo costosa y había un solo microprocesador. Teradata, Sequent y Tandem crearon configuraciones de hardware para mayor capacidad. En los noventas llegó el almacenamiento en red y mejoras incrementales con procesadores de 64 bits.
Actualidad
Las economías alrededor del cómputo han cambiado gracias a los avances en hardware. Son comunes los servidores con múltiples procesadores/núcleos, los sistemas de 4 y 8 vías son accesibles, la memoria es mucho más económica, los discos duros son de mayor capacidad y mucho menor costo.
Aún así, esta tercera generación de gestores de base de datos opera básicamente de la misma forma que la anterior, aunque los efectos de escalabilidad, desempeño, administración y ahorro en costo son dramáticamente mayores gracias a los avances de la tecnología.
Futuro cercano
En los últimos años se han estado gestando innovaciones que poco a poco han ido permeando a los sistemas de base de datos. Aquí algunos de los más significativos:
Base de datos en memoria. La forma en que los datos están organizados y se manejan es totalmente diferente. Se usan estructuras de datos simples, se eliminan problemas de transferencia de información. Una operación se puede ejecutar de 20 a 200 veces más rápido que en sistemas convencionales. El acceso óptimo es en forma de interfaz de programación (APIs). Sybase, Oracle, Four Js y otros ofrecen algunas de estas capacidades.
Almacenamiento columnar. Para análisis estadístico, como almacenes de datos, es posible almacenar columnas en lugar de renglones, reduciendo la entrada y salida en forma significativa.
Almacenamiento no relacional. Para agregar grandes cantidades de datos y realizar operaciones de búsqueda ha aparecido éste modelo. BigTable de Google, SimpleDB de Amazon y Azure Storage de Microsoft son ejemplos. Algunos proveen funcionalidad para administrar documentos XML, como Tierlogic, Tamino, XMS. Los sistemas tradicionales incluyendo a Oracle, IBM y Microsoft han extendido sus productos a tipos de datos geográficos y no-estructurados.
La nube. Ofrece por primera vez la verdadera posibilidad de almacenamiento ilimitado. Bases de datos en data centers internos pueden “extenderse” a operar en centros de datos públicos. Microsoft SQL Azure es el mejor ejemplo.

Sensores y tiempo real. En el mundo de los sistemas embebidos que manejan tecnologías como RFID y eventos en Internet, se hace necesario analizar la información y tomar acción en memoria y antes de almacenar datos. StreamInsight es una nueva característica en la reciente liberación de Microsoft SQL Server 2008 “R2”.
Con certeza veremos la aparición de una nueva generación de sistemas de base de datos durante los siguientes 3 años, y la gran batalla que la misma conllevará. Lo popular y lo gratuito está bien, pero ahí no está la innovación ni las nuevas oportunidades.
Presente y futuro de las bases de datos relacionales con Big Data
Hace unos días me preguntaba un cliente mi opinión sobre el futuro de las bases de datos relacionales respecto al progresivo aumento de popularidad de las bases de datos NoSQL en los últimos años.
Es conocido por todos que cada vez se generan más y más datos, y el escalado vertical (scale-up) que ofrecen las bases de datos relacionales, en principio, no parece una buena solución respecto al escalado horizontal (scale-out) de los entornos distribuidos de las principales bases de datos NoSQL.

Basándonos en esto y viendo que el incremento de volumen de datos avanza a una velocidad mayor que el incremento de capacidad del hardware, es normal pensar que tarde o temprano, las bases de datos relacionales se van a quedar cortas.
Para analizar cómo afrontan hoy en día y qué opciones de futuro planean las bases de datos relacionales respecto a estos problemas, vamos a diferenciar los dos tipos de entornos que principalmente existen.
Por un lado tenemos entornos datawarehouse (DW), entornos analíticos donde la información se carga en batches y se transforma quedando generalmente estática para favorecer el reporting y explotación de la misma.
Por otro lado tenemos los entornos transaccionales (OLTP), entornos operacionales donde la información está viva, y en los cuales se favorece el rendimiento de estas frecuentes modificaciones.
Entornos datawarehouse
Hoy en día, la apuesta en este tipo de entornos de las bases de datos relacionales es claramente el almacenamiento de la información de forma columnar.
A diferencia del almacenamiento tradicional de la información en este tipo de bases de datos en forma de registros, el almacenamiento de la información de cada columna de forma conjunta ofrece un ratio de compresión de tamaño de los datos superior al 80% en la mayoría de casos.
Debido a esta significativa compresión es mas fácil mantener esos datos en memoria, añadido a la capacidad de procesar la información en batches de registros, ofrece un rendimiento muy competitivo sobre todo en consultas de agregación.
Tanto SQL Server, desde la versión 2012, como Oracle, desde la 12c, ofrecen sus tecnologías columnstore integradas en su propio motor de base de datos.
Basándose en esta tecnología, y hablando de cantidades ingentes de datos, no se quedan atrás y ofrecen soluciones en la nube distribuidas en entornos de procesamiento masivo en paralelo (MPP).
Respecto a SQL Server tenemos Azure SQL Data warehouse, anteriormente conocido como SQL Server Parallel Data Warehouse.
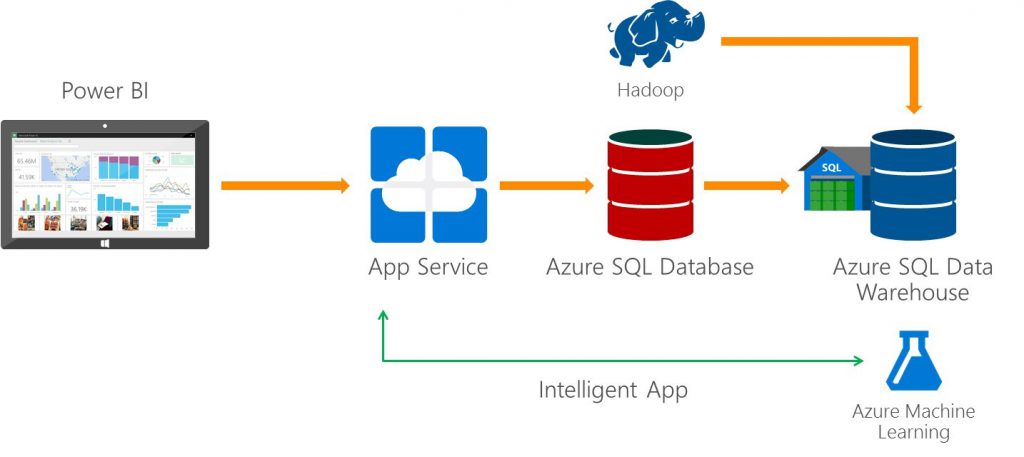
En este tipo de entornos, tanto para relacionales como para NoSQL, el objetivo es claro, mantener los datos en memoria y evitar accesos a disco.
Debido a que, tanto la velocidad de acceso como de escritura es mucho mayor en memoria que en disco, el único uso de la memoria para realizar las operaciones en este tipo de entornos es critica para el buen rendimiento de las mismas.
Hoy en día SQL Server, desde la versión 2014, ofrece su tecnología en memoria (In-Memory OLTP) integrada en el motor de base de datos.
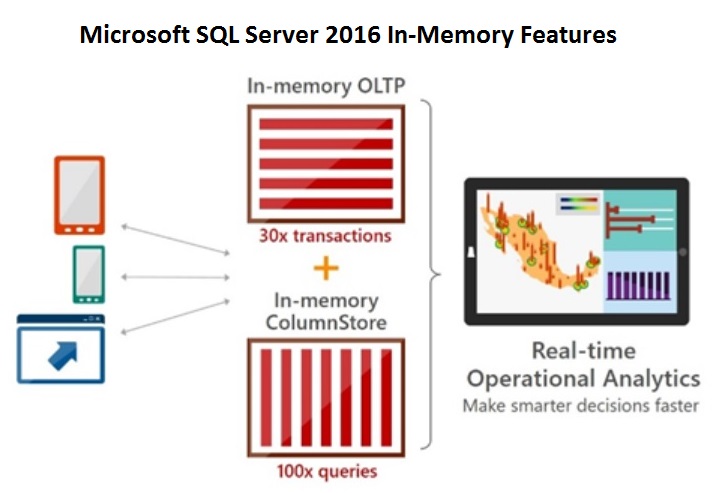
Hablando de Oracle, han anunciado la versión para datawarehouses de su nueva base de datos Oracle 18c para Diciembre de 2017, distribuida y autónoma tanto en cloud privada como pública.

Links
Comentarios
Publicar un comentario